Training
When you submit a training job, the request is added to the job queue. If
you do not already have a running job in the same project, and when a GPU
runner is available, it will pop the job out of the queue and download the
dataset to its local disk - the job is starting.
After that, the training process actually begins - the job is running, and your model is learning.
At any point, you can stop the job before it is done. The runner will make sure
to checkpoint the model before it shuts itself down. Whether the job naturally
ends or you stop it before then, the local copy of your dataset is deleted.
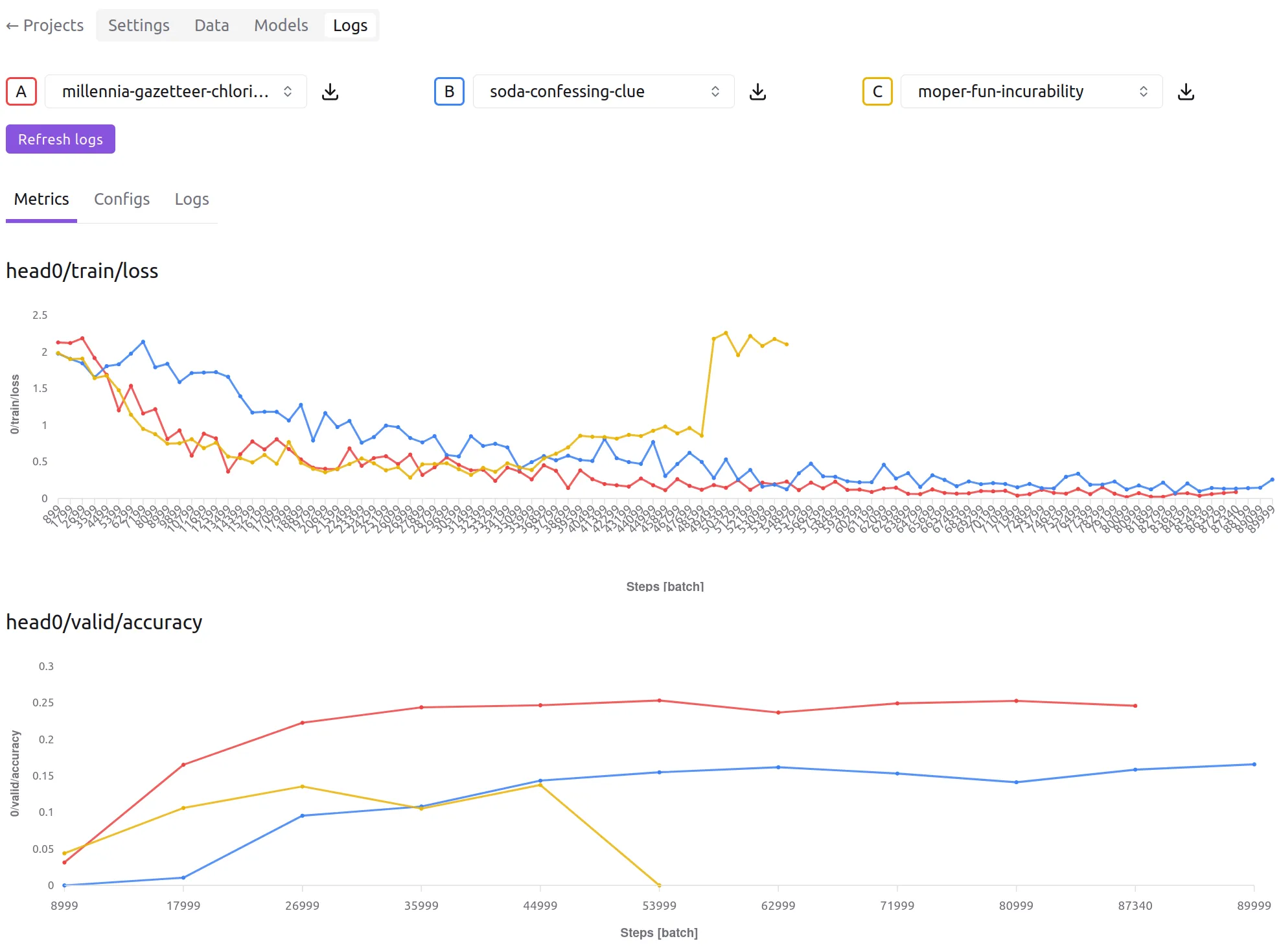
While the model trains, you can check its live metrics and logs. The metrics
graphs inform engineers about how to adjust certain hyperparameters for the
next experiment. You can also compare the metrics (and configs) with
previous jobs in the project, to see how the difference in hyperparameters
or dataset influence the performance, and in what way.
In case the job encounters a error, you should check the logs to get information
about the source cause, and contact us at
support@sihl.ai to get help
solving the issue.
Some tasks solve similar problems, and their corresponding datasets can
encode similar information. It is therefore not suprising that some tasks
can be converted into (or interpreted as) some other task type. For example,
you can train a multilabel classification model from an object detection dataset by looking at the categories of the objects in each image and ignoring
the bounding boxes.
For your convenience, Sihl AI can automatically perform certain task conversions:
flowchart TB
IS("instance segmentation")
KD("keypoint detection")
QD("quadrilateral detection")
OD("object detection")
MLC("multilabel classification")
MCC("multiclass classification")
PS("panoptic segmentation")
SS("semantic segmentation")
ML("metric learning")
PS --> SS & IS
IS --> OD
QD <--> OD
KD --> OD
OD & SS --> MLC
MCC <--> ML
MCC --> MLC
These task conversions are composable, meaning you can, for example, convert
an instance segmentation dataset to multilabel classification since there
exists at least one conversion path.
In addition to the above, all tasks can be converted into any of the self-supervised
tasks, since those ignore annotations anyway.
Sihl AI models can train on multiple tasks at the same time, due their meta-architecture supporting multiple heads for a unique common backbone (and neck). Note that you can train on mutiple task types or several of the same type (or a combination of both).
Multitask training is obviously needed to fit multitask datasets, but this feature can also be useful to enhance single task datasets, by
leveraging task type conversions.
You could, for instance, perform semi-supervised learning by adding an extra
self-supervised task (e.g. view-invariance learning) to a partly-annotated dataset for a supervised task (e.g. regression). This setup is still useful even if the dataset is fully labeled, as
training such an auxiliary head can sometimes improve generalization.