Quickstart
Sihl AI is an automated neural network training service.
We find that automation shortens development time and increases projects' chance
of success.
Here's how it works:
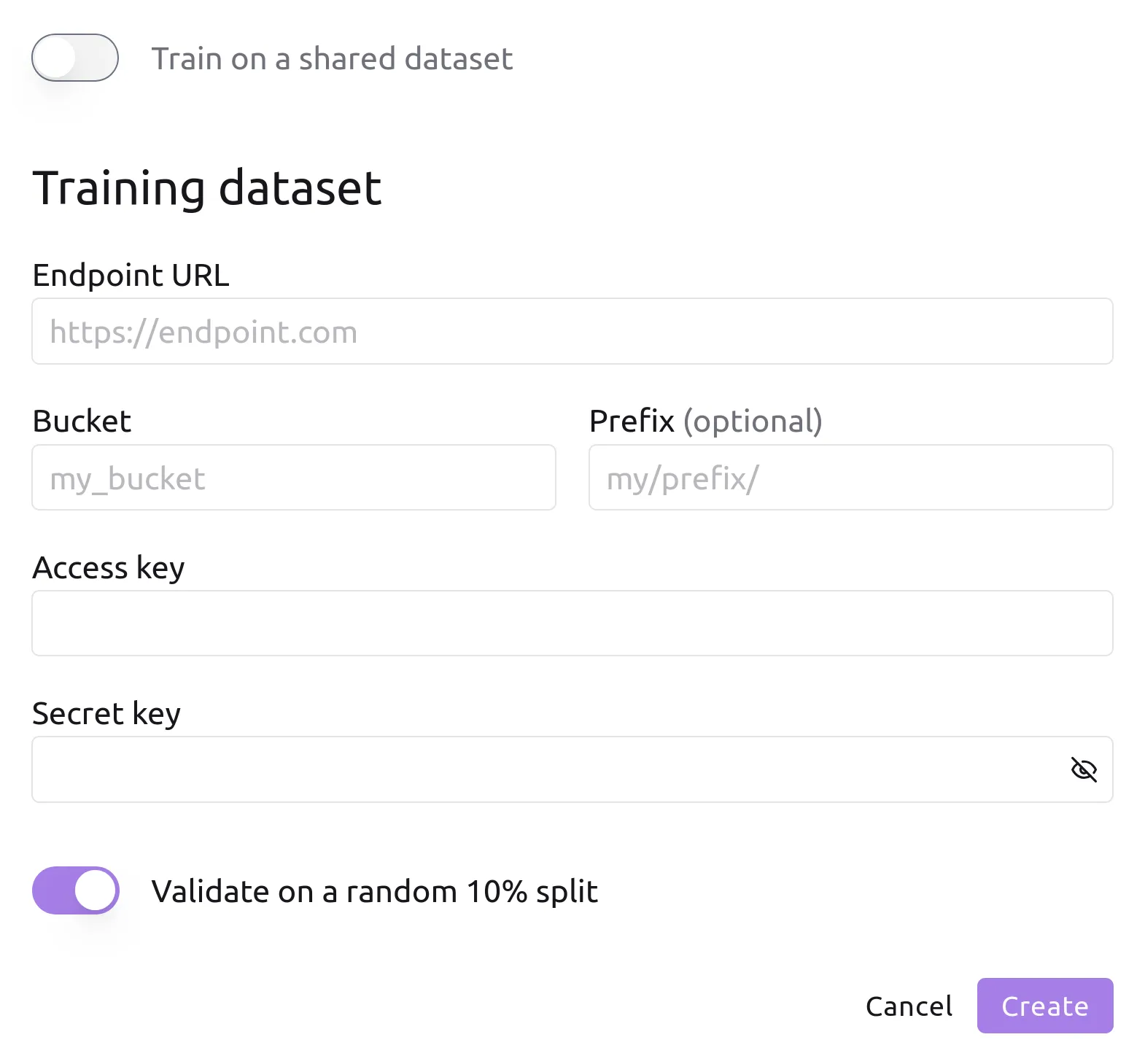
A Sihl AI project is associated to a single dataset stored at any
S3-compatible object storage.
We support cloud solutions like AWS S3 and on-premise solutions like MinIO. In either case, you retain full control over your data, and we only
ever access it for model training.
By default, we randomly split off 10% of the dataset to validate the model
during the training process. However, you can optionally link a project to
explicit training and validation sets, which is useful to validate
generalization ability.
We supply foundation datasets from
which you can create pre-training projects easily. These datasets are made
available for everyone to conveniently train on, but the underlying images
cannot be downloaded for legal reasons.
 Datasets must be annotated to train most tasks. Only self-supervised tasks
like autoencoding
or view-invariance learning support unlabeled datasets of images.
Datasets must be annotated to train most tasks. Only self-supervised tasks
like autoencoding
or view-invariance learning support unlabeled datasets of images.
Right before a model starts training, the runner will download the dataset
onto its local disk to accelerate the training process. Once the model is
done training, the local copy is deleted. We will never keep, share,
or sell your datasets.
A project admin (by default, its creator) can change the dataset storage
details anytime.
Once a project is created, you can start training models by submitting
training jobs, that one of our GPU runners will pick up and perform.
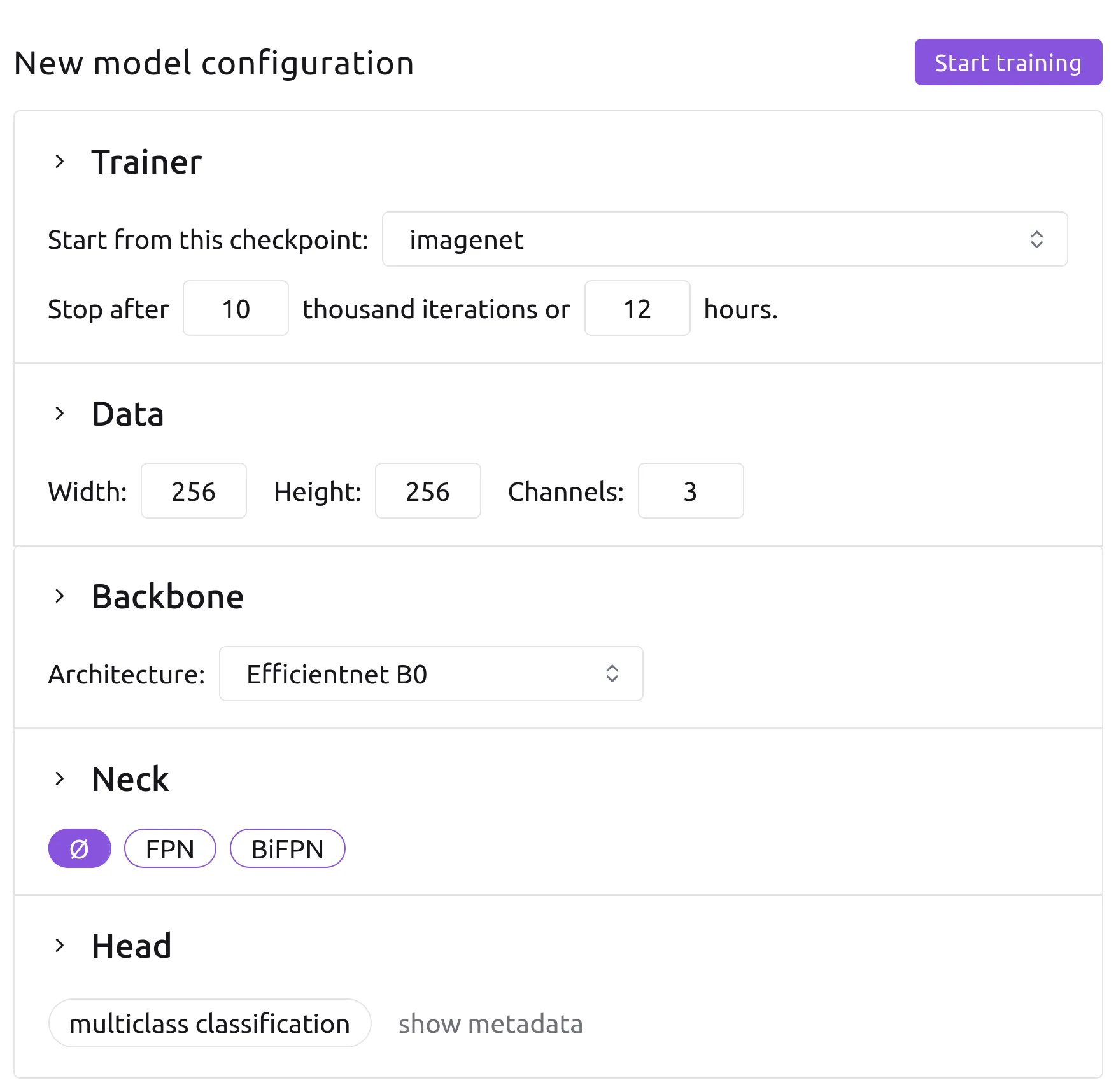
A training job is configured by hyperparameters, which have default values you can adjust to precisely control the
training process.
Most of these are hidden under the collapsible fold, but the most important
ones are always shown, and we recommend you always check these. They include:
- weight initialization (imagenet or a checkpoint from any of the projects you are a member of)
- training duration (in iterations and/or hours, to cap the cost of the job)
- image size (all training images need to be resized to be batched for training)
- backbone architecture (from small and fast to big and performant)
Your job will run immediately if you do not already have a running job in
the same project, in which case the new job will be queued until the first
one stops. This means that all members of a project can each have one job
running concurrently. A given user can also run concurrent jobs in
different projects. If you need to run concurrent jobs in a single
project, let us know at support@sihl.ai.
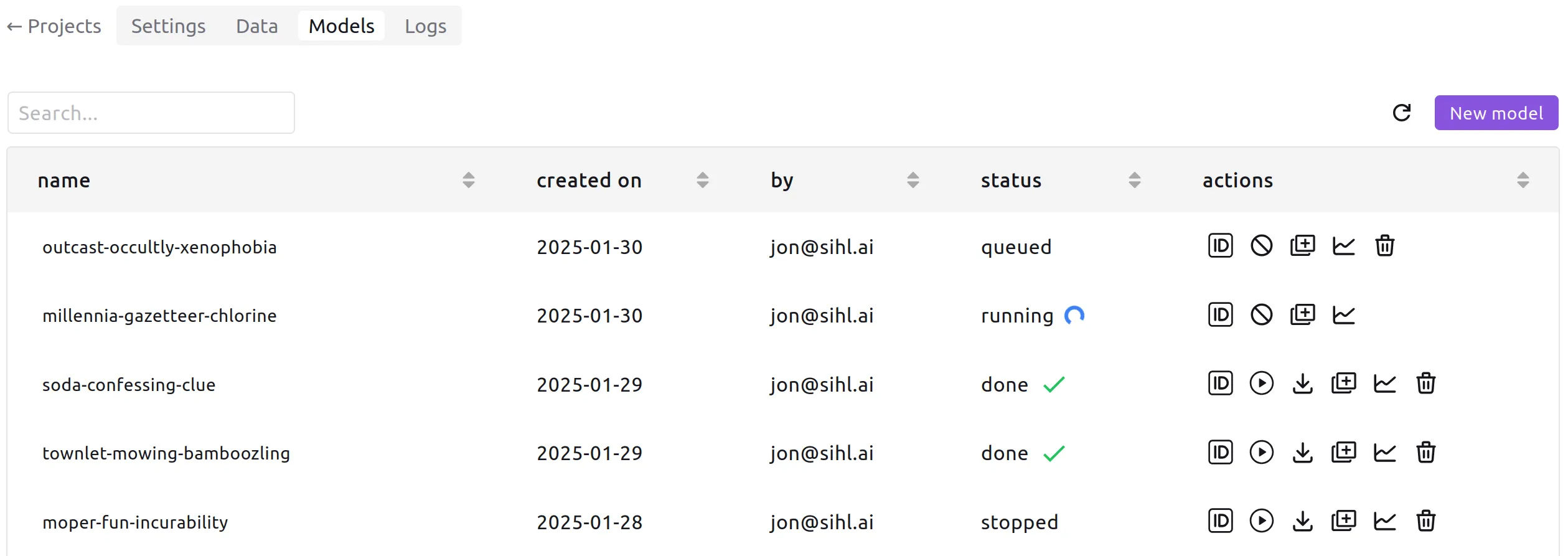 While the model trains, you can view its live-updated metrics and logs, and
compare those with other models of the project. You can also "duplicate" the
job, copying over all the hyperparameters to let you change just what you need
before submitting.
While the model trains, you can view its live-updated metrics and logs, and
compare those with other models of the project. You can also "duplicate" the
job, copying over all the hyperparameters to let you change just what you need
before submitting.
Once a model is trained, you have several options to run it.
To quickly test it out, you can just drag-and-drop an image into your browser.
Your browser will then automatically forward it to an endpoint serving your
model and return its outputs. This is the easiest and quickest way to run inference,
but it has a couple drawbacks. First, you cannot process a batch of images
this way, it only supports single image inference. Second, the first call to
this endpoint will incur extra latency due to needing to download your model
before running it; subsequent calls will be much faster due to your model being
cached.
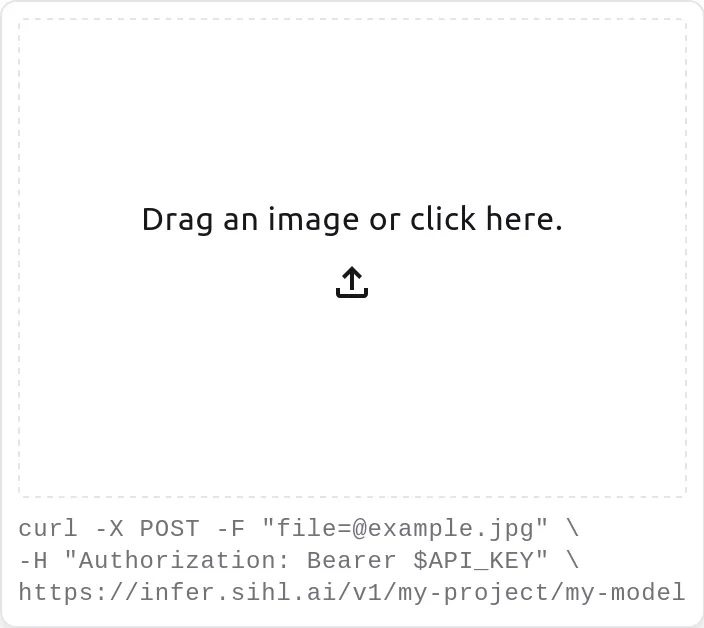 Alternatively, you can call the API endpoint programmatically, from a
shell script or Python for example. The same limitations as above apply
here.
Alternatively, you can call the API endpoint programmatically, from a
shell script or Python for example. The same limitations as above apply
here.
If you need consistently low latency, batched inference, or to run
inference at the edge, you can export the model and run your own inference
server. We support ONNX (FP32 or INT8) and TensorRT (FP16) formats optimized for inference, and pytorch state dict (to be used with our open-source code) for other use-cases.
Exported model completely are license-free - you can use them however you want,
including commercially!